Published on: Jan 14, 2025
Semantic Cache: Supercharging Agentic AI with Distributed Semantic Search
I. Introduction
Traditional caching systems require exact key matches to retrieve data. But what if you could find cached information by meaning instead? This is the core idea behind Semantic Cache - a distributed key-value store I built that combines the speed of traditional caching with the intelligence of semantic search.
In the world of agentic AI, where autonomous agents need to reason, remember, and act without constant human guidance, semantic caching becomes a game-changer. Instead of agents repeating expensive computations or API calls for semantically similar queries, they can retrieve relevant past results instantly.
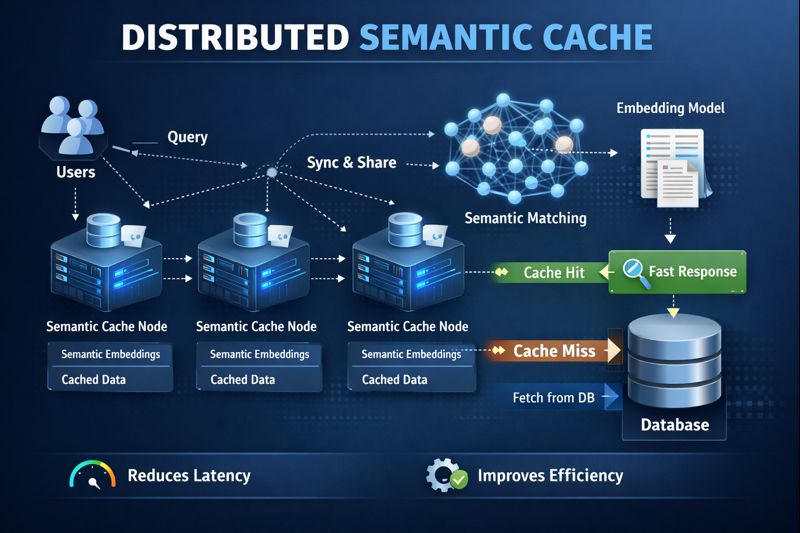
II. The Problem with Traditional Caching
Traditional caching systems like Redis or Memcached are incredibly fast, but they have a fundamental limitation: they only work with exact key matches.
Consider this scenario in an agentic AI system:
1# Agent caches a response
2cache.set("How to optimize database queries?", response_1)
3
4# Later, a semantically similar question comes in
5cache.get("database query optimization techniques") # Returns None!The second query is semantically identical to the first, but traditional caches miss this connection entirely. The agent must recompute or re-fetch the answer, wasting time and resources.
Semantic Cache solves this by indexing data with vector embeddings and enabling similarity-based retrieval:
1# Store with semantic indexing
2semantic_kv.put("optimize-db-001", {
3 "query": "How to optimize database queries?",
4 "response": "Use indexing, query optimization, caching..."
5})
6
7# Search by meaning - finds the relevant cached response!
8results = semantic_kv.search("database query optimization techniques", top_k=3)III. Technology Stack
Apache Arrow: The Foundation
Apache Arrow is a cross-language development platform for in-memory columnar data. The semantic cache uses Arrow in two critical ways:
1. Arrow IPC for Persistence
The persistence layer uses Arrow's IPC (Inter-Process Communication) format to serialize KV entries to disk. The schema is defined as:
1KV_SCHEMA = pa.schema([
2 ('key', pa.string()),
3 ('value', pa.large_binary()),
4 ('embedding', pa.list_(pa.float32())),
5 ('created_at', pa.int64()),
6 ('ttl_ms', pa.int64()),
7 ('access_count', pa.int64()),
8 ('last_accessed', pa.int64()),
9])This columnar format provides:
- Efficient compression: Similar data types stored together compress better
- Fast partial reads: Can read only specific columns without loading entire records
- Zero-copy deserialization: Data can be memory-mapped directly without parsing
- Cross-language compatibility: Arrow files can be read by Python, C++, Java, Rust, etc.
2. Arrow Flight for Network Communication
Arrow Flight is a high-performance RPC framework built on gRPC and Arrow. Each node in the cluster is a Flight server that handles operations via the do_action protocol:
1class SemanticKVNode(flight.FlightServerBase):
2 def do_action(self, context, action):
3 action_type = action.type
4 body = action.body.to_pybytes()
5
6 if action_type == "put":
7 return self._action_put(body)
8 elif action_type == "get":
9 return self._action_get(body)
10 elif action_type == "search_local":
11 return self._action_search_local(body)
12 # ... other actionsAvailable Flight actions:
| Action | Description |
|---|---|
put | Store key-value pair with embedding |
put_replica | Store replica (internal, from other nodes) |
get | Exact key lookup with TTL check |
search_local | Semantic search on local HNSW index |
delete | Remove key from store and index |
scan | List keys by prefix |
stats | Return node statistics |
health | Health check |
clear | Clear all data |
Why Arrow Flight over plain gRPC?
- Native columnar data: Perfect for batch operations and large result sets
- Zero-copy semantics: Data moves directly from network buffer to application
- Built-in streaming: Efficient for large result sets without loading all into memory
- Standard protocol: Interoperable with Arrow ecosystem (Spark, Pandas, DuckDB)
IV. In-Memory Storage Architecture
Primary Storage: Python Dictionary
The cache operates as an in-memory first system. Each node maintains data in a Python dictionary with KVEntry dataclass objects:
1@dataclass
2class KVEntry:
3 key: str
4 value: bytes
5 embedding: np.ndarray # Vector embedding (384-3072 dims)
6 created_at: int # Timestamp (milliseconds)
7 ttl_ms: int # Time-to-live (0 = no expiration)
8 access_count: int = 0 # Access statistics
9 last_accessed: int = 0 # Last access timestamp
10
11# Storage structure
12self._store: Dict[str, KVEntry] = {}Thread Safety
All operations are protected by a reentrant lock (threading.RLock):
1def _action_get(self, body: bytes):
2 key = body.decode()
3
4 with self._lock: # Thread-safe access
5 if key not in self._store:
6 return [flight.Result(b"")]
7
8 entry = self._store[key]
9
10 # Check expiration
11 if self._is_expired(entry):
12 self._delete_entry(key)
13 return [flight.Result(b"")]
14
15 # Update access stats
16 entry.access_count += 1
17 entry.last_accessed = int(time.time() * 1000)
18
19 return [flight.Result(entry.value)]TTL Expiration
Entries support time-to-live with lazy expiration checking:
1def _is_expired(self, entry: KVEntry) -> bool:
2 if entry.ttl_ms <= 0:
3 return False # No expiration
4 now_ms = int(time.time() * 1000)
5 return (now_ms - entry.created_at) > entry.ttl_msV. Persistence Layer
While the primary storage is in-memory, the system provides durable persistence through the ArrowKVStore class:
Saving Data
1class ArrowKVStore:
2 def save(self, entries: Dict[str, KVEntry], index=None, metadata=None):
3 # Convert entries to Arrow table
4 keys, values, embeddings = [], [], []
5 for key, entry in entries.items():
6 keys.append(key)
7 values.append(entry.value)
8 embeddings.append(entry.embedding.tolist())
9
10 table = pa.Table.from_arrays([
11 pa.array(keys),
12 pa.array(values, type=pa.large_binary()),
13 pa.array(embeddings, type=pa.list_(pa.float32())),
14 # ... other columns
15 ], schema=KV_SCHEMA)
16
17 # Write to Arrow IPC file
18 with pa.OSFile(str(self._data_file), 'wb') as sink:
19 writer = ipc.new_file(sink, table.schema)
20 writer.write_table(table)
21 writer.close()Loading Data
1def load(self) -> Tuple[List[PersistedEntry], Dict]:
2 # Memory-map the Arrow file for zero-copy reads
3 with pa.memory_map(str(self._data_file), 'r') as source:
4 reader = ipc.open_file(source)
5 table = reader.read_all()
6
7 entries = []
8 for i in range(table.num_rows):
9 entry = PersistedEntry(
10 key=table['key'][i].as_py(),
11 value=table['value'][i].as_py(),
12 embedding=np.array(table['embedding'][i].as_py()),
13 # ... other fields
14 )
15 entries.append(entry)
16
17 return entries, metadataHNSW Index Persistence
The HNSW index is persisted separately using hnswlib's native format:
1# Saving
2index.save_index(str(self._index_file))
3
4# Loading
5index = hnswlib.Index(space='cosine', dim=dim)
6index.load_index(str(self._index_file))Snapshot Manager
For backup and recovery, the SnapshotManager provides:
1class SnapshotManager:
2 def create_snapshot(self, name: str = None):
3 # Copy all data files to snapshot directory
4 shutil.copytree(
5 self._data_dir,
6 snapshot_dir,
7 ignore=shutil.ignore_patterns('snapshots')
8 )
9
10 def restore_snapshot(self, name: str):
11 # Remove current data, copy snapshot back
12 ...VI. Cluster Formation and Topology
Static Node Configuration
The cluster uses a static configuration model where nodes are known at startup:
1# Client connects to pre-configured nodes
2client = DistributedSemanticKV([
3 "grpc://node1:8815",
4 "grpc://node2:8816",
5 "grpc://node3:8817",
6 "grpc://node4:8818",
7])Each node is an independent Flight server:
1# Start individual nodes
2node1 = SemanticKVNode(
3 location="grpc://0.0.0.0:8815",
4 node_id="node-1",
5 embedding_provider=SentenceTransformerEmbedding(),
6)
7node1.serve() # Blocks, runs gRPC serverConnection Pooling
The client maintains a lazy connection pool with thread-safe initialization:
1def _get_client(self, node: str) -> flight.FlightClient:
2 with self._clients_lock:
3 if node not in self._clients:
4 self._clients[node] = flight.FlightClient(node)
5 return self._clients[node]Retry Logic with Backoff
Failed operations are retried with exponential backoff:
1def _execute_with_retry(self, node, action_type, body, retries=2):
2 for attempt in range(retries + 1):
3 try:
4 client = self._get_client(node)
5 action = flight.Action(action_type, body)
6 results = list(client.do_action(action))
7 return results[0].body.to_pybytes()
8 except Exception:
9 # Remove stale connection, backoff, retry
10 del self._clients[node]
11 time.sleep(0.1 * (attempt + 1))VII. Query Distribution: Consistent Hashing
How Consistent Hashing Works
The system uses consistent hashing with virtual nodes to distribute keys across the cluster. The implementation uses MD5 hashing:
1class ConsistentHashRing:
2 def __init__(self, nodes: List[str], virtual_nodes: int = 150):
3 self._virtual_nodes = virtual_nodes
4 self._ring: List[Tuple[int, str]] = []
5
6 for node in nodes:
7 self.add_node(node)
8
9 def _hash(self, key: str) -> int:
10 return int(hashlib.md5(key.encode()).hexdigest(), 16)
11
12 def add_node(self, node: str):
13 # Add virtual nodes for even distribution
14 for i in range(self._virtual_nodes):
15 virtual_key = f"{node}:vnode:{i}"
16 hash_val = self._hash(virtual_key)
17 self._ring.append((hash_val, node))
18
19 # Sort for binary search
20 self._ring.sort(key=lambda x: x[0])Virtual Nodes for Even Distribution
With 150 virtual nodes per physical node:
- Even key distribution: Keys spread uniformly across nodes
- Minimal reshuffling: Adding/removing a node only remaps ~1/N keys
- O(log n) lookups: Binary search on sorted ring
1def get_node(self, key: str) -> str:
2 hash_val = self._hash(key)
3
4 # Binary search for first node with hash >= key hash
5 idx = bisect_right(self._hash_values, hash_val)
6
7 # Wrap around if past the end
8 if idx >= len(self._ring):
9 idx = 0
10
11 return self._ring[idx][1]Operation Routing Patterns
Different operations use different routing strategies:
| Operation | Strategy | Description |
|---|---|---|
put(key, value) | Deterministic | Hash key -> single responsible node |
get(key) | Deterministic | Hash key -> single responsible node |
delete(key) | Deterministic | Hash key -> single responsible node |
search(query) | Scatter-Gather | Query ALL nodes -> merge by similarity |
scan(prefix) | Scatter-Gather | Query ALL nodes -> deduplicate keys |
PUT: Deterministic Write
1def put(self, key: str, value: bytes, ttl_ms: int = 0) -> bool:
2 # Hash determines the single responsible node
3 node = self._ring.get_node(key)
4
5 data = json.dumps({
6 'key': key,
7 'value': list(value),
8 'ttl_ms': ttl_ms
9 })
10
11 result = self._execute_with_retry(node, "put", data.encode())
12 return result == b"ok"GET: Deterministic Read
1def get(self, key: str) -> Optional[bytes]:
2 # Same hash -> same node as PUT
3 node = self._ring.get_node(key)
4
5 result = self._execute_with_retry(node, "get", key.encode())
6 return result if result else NoneSEARCH: Scatter-Gather
Semantic search must query all nodes because similar items may be distributed anywhere:
1def search(self, query: str, top_k: int = 10, threshold: float = 0.7):
2 params = json.dumps({
3 'query': query,
4 'top_k': top_k,
5 'threshold': threshold
6 })
7
8 def search_node(node: str) -> List[dict]:
9 result = self._execute_with_retry(node, "search_local", params.encode())
10 return json.loads(result.decode()) if result else []
11
12 # SCATTER: Query all nodes in parallel
13 all_nodes = self._ring.get_all_nodes()
14 futures = {
15 self._executor.submit(search_node, node): node
16 for node in all_nodes
17 }
18
19 # GATHER: Collect results with timeout
20 all_results = []
21 for future in as_completed(futures, timeout=self._search_timeout):
22 node_results = future.result()
23 all_results.extend(node_results)
24
25 # MERGE: Sort by similarity, return top-k
26 all_results.sort(key=lambda x: x['similarity'], reverse=True)
27 return all_results[:top_k]The thread pool uses nodes * 2 workers by default for parallel operations:
1self._executor = ThreadPoolExecutor(max_workers=len(nodes) * 2)VIII. Vector Indexing with HNSW
HNSW Algorithm
HNSW (Hierarchical Navigable Small World) is a state-of-the-art algorithm for approximate nearest neighbor search:
1self._index = create_vector_index(
2 dim=self._embedding_provider.dimension, # 384-3072
3 max_elements=max_entries, # 100,000 default
4 ef_construction=200, # Build quality
5 M=16, # Connections per node
6 ef_search=50 # Search quality
7)Index Operations
Each node maintains its own HNSW index with bidirectional mappings:
1# Mappings between keys and index positions
2self._key_to_idx: Dict[str, int] = {}
3self._idx_to_key: Dict[int, str] = {}
4self._next_idx = 0
5
6# Adding to index during PUT
7idx = self._next_idx
8self._index.add_items(embedding.reshape(1, -1), [idx])
9self._key_to_idx[key] = idx
10self._idx_to_key[idx] = key
11self._next_idx += 1Local Semantic Search
1def _action_search_local(self, body: bytes):
2 params = json.loads(body.decode())
3 query = params['query']
4 top_k = params.get('top_k', 10)
5 threshold = params.get('threshold', 0.7)
6
7 # Generate query embedding
8 query_embedding = self._get_embedding(query)
9
10 # Search HNSW index
11 k = min(top_k, self._index.get_current_count())
12 labels, distances = self._index.knn_query(
13 query_embedding.reshape(1, -1),
14 k=k
15 )
16
17 results = []
18 for label, dist in zip(labels[0], distances[0]):
19 # Cosine distance to similarity
20 similarity = 1.0 - dist
21
22 if similarity >= threshold:
23 key = self._idx_to_key[label]
24 entry = self._store[key]
25
26 results.append({
27 'key': key,
28 'value': entry.value.decode(),
29 'similarity': float(similarity),
30 'node': self.node_id
31 })
32
33 return [flight.Result(json.dumps(results).encode())]IX. Embedding Providers
Three embedding backends are supported:
SentenceTransformers (Recommended)
1from sentence_transformers import SentenceTransformer
2
3class SentenceTransformerEmbedding:
4 def __init__(self, model_name="all-MiniLM-L6-v2"):
5 self.model = SentenceTransformer(model_name)
6 self.dimension = self.model.get_sentence_embedding_dimension()
7
8 def embed(self, text: str) -> np.ndarray:
9 return self.model.encode(text, convert_to_numpy=True)OpenAI Embeddings (Premium)
1import openai
2
3class OpenAIEmbedding:
4 def __init__(self, model="text-embedding-3-small"):
5 self.client = openai.OpenAI()
6 self.model = model
7
8 def embed(self, text: str) -> np.ndarray:
9 response = self.client.embeddings.create(
10 input=text,
11 model=self.model
12 )
13 return np.array(response.data[0].embedding)X. Performance Characteristics
Benchmarked on a 4-node localhost cluster:
| Operation | Throughput | Avg Latency | P99 Latency |
|---|---|---|---|
| GET (hit) | 7,195 ops/sec | 0.14 ms | 0.18 ms |
| GET (miss) | 6,288 ops/sec | 0.16 ms | 0.62 ms |
| PUT (100B) | 3,579 ops/sec | 0.28 ms | 0.43 ms |
| PUT (1KB) | 2,721 ops/sec | 0.37 ms | 0.46 ms |
| DELETE | 7,100 ops/sec | 0.14 ms | 0.20 ms |
| SEARCH (1K keys) | 344 ops/sec | 2.91 ms | 3.37 ms |
| SEARCH (10K keys) | 46 ops/sec | 21.59 ms | 30.48 ms |
| SCAN | 1,396 ops/sec | 0.72 ms | 0.86 ms |
XI. Use Cases in Agentic AI
1. Query Caching for Agent Memory
1# Store reasoning with semantic indexing
2kv.put_json("reasoning:001", {
3 "query": "How to handle authentication errors?",
4 "response": "Check token expiration, refresh if needed...",
5 "confidence": 0.95
6})
7
8# Later, find relevant past reasoning
9results = kv.search("authentication token expired", top_k=5)2. Tool Discovery by Capability
1# Store tool metadata
2kv.put_json("tool:sql-executor", {
3 "name": "SQL Executor",
4 "description": "Executes parameterized SQL queries"
5})
6
7# Agent searches for relevant tools
8tools = kv.search("execute database queries", top_k=3)3. Multi-Agent Knowledge Sharing
1# Agent A discovers rate limit
2agent_a.put_json("discovery:rate-limit", {
3 "endpoint": "/api/users",
4 "limit": "100 req/min"
5})
6
7# Agent B searches without knowing exact key
8results = agent_b.search("API rate limiting", top_k=1)4. Conversation Context Retrieval
1# Store conversation turns
2kv.put_json("conv:turn:42", {
3 "user": "What files are in the project?",
4 "assistant": "[directory listing]"
5})
6
7# Retrieve relevant context
8context = kv.search("explore project structure", top_k=5)XII. Getting Started
Installation
1pip install semantic-kvStart a Cluster
1from semantic_kv import SemanticKVNode, DistributedSemanticKV
2
3# Start nodes (in separate processes)
4node1 = SemanticKVNode(location="grpc://0.0.0.0:8815", node_id="node-1")
5node2 = SemanticKVNode(location="grpc://0.0.0.0:8816", node_id="node-2")
6
7# Connect client
8client = DistributedSemanticKV([
9 "grpc://localhost:8815",
10 "grpc://localhost:8816"
11])Basic Operations
1# Store data
2client.put("key1", b"value1")
3client.put_json("user:123", {"name": "Alice", "role": "admin"})
4
5# Exact retrieval
6value = client.get("key1")
7user = client.get_json("user:123")
8
9# Semantic search
10results = client.search("find admin users", top_k=5, threshold=0.7)
11for key, value, similarity, node in results:
12 print(f"Key: {key}, Score: {similarity:.2f}")XIII. Conclusion
Semantic Cache bridges the gap between traditional caching systems and modern AI requirements. The key architectural decisions:
- Apache Arrow Flight for high-performance RPC with zero-copy semantics
- Arrow IPC format for efficient persistence and cross-language compatibility
- In-memory primary storage with optional disk persistence
- Consistent hashing for deterministic key routing with minimal reshuffling
- Scatter-gather pattern for distributed semantic search
- HNSW indexing for sub-millisecond vector similarity search
This combination enables agentic AI systems to:
- Find relevant past experiences by meaning
- Avoid redundant computations
- Share knowledge across agents naturally
- Scale horizontally with demand
Related Reading: